There are many possible operational scenarios where biometrics are involved. In this power I will attempt to give some ingith in the possible scenarios and the effect on the type of biometrics required and the associated settings and procedures. The most practival use of this post is to use it as a reference for determining if you ‘best’ fused ROC curve is good enough for the scenario you have in mind. Use the thougts presented in this chapter to choose a final threshold wisely.
Classification
You can think of many biometrics applications. For example gaining access to a secure building using an iris scan, verifying at a border control that the visum is the same person as to whom it was issued or perhaps a surveillance camera on an airport looking for a known terrorist.
I propose to divde such applications in 6 categories. One element is the database size, which can be tiny, medium or large. The other element is the database purpose, either a blacklist or whitelist.
Database sizes
The database sizes can be tiny, medium or large. A typical tiny database is a chip on a passport, the owner data of a laptop or the information on a smartcard. A medium database can be a watchlist with known terrorists or a list of employees for a company. Large databases typically will contain all people that applied for a visa through foreign embassies or all people that have been issued a certain smartcard.
White and Black
The records in a database can be either a whitelist or a blacklist. A whitelist can contain biometric data of people with certain privileges like access to a building or fingerprints of people who have succesfully applied for a visa. Adversaries of such a system will typically try to be identified as a person on a whitelist.
A blacklist will contain people that deserve special attention from the owner of a biometrics system. For example a camera surveillance system can use a blacklist to identify criminals in shops, or alternatively a fingerprint system can check for known terrorists at border crossings. Adversaries of such a system will usually try to avoid being identified as a person on a blacklist.
Examples
As with most concepts, they are best explained through some examples.
Tiny whitelists
Tiny whitelists can be e-passports, smartcards or biometric information on a personal laptop.
Tiny blacklists
Probably the odd one out in this list because it has few realistic use-cases (keeping just a small number of people out). A possible example could be the biometrics of an operator at an enrollment station to avoid fraud.
Medium whitelists
Secure access to a company building falls into this category. Also identifying people in a closed environment is a good example. For example it can be known which people are in an airport terminal, making it much easier to identity someone in there.
Medium blacklists
A watchlist is a good example of this. People on such a list can be terrorists, repeat offenders or people denied access to a private club.
Large whitelists
All people hat have been issued an e-passport can be registered in a database like this, a person will then still be identifiable if the e-passport gets lost or unreadable. Also people that have been issued a visa will be in such a database.
Large blacklists
If biometrics are coupled to some entitlement or license, there should be a de-duplication process to ensure that a single person does not apply twice, here you effectively use the entire already enrolled population as a blacklist.
Consequence of errors
The two types of error that can be made by a biometrics system (false match and false non-match) have different implications depending on whether the system is a whitelist or a blacklist based system. For a blacklist based system a false match may result in an innocent civilian being brought in for questioning. Or in case of some entitlement, it may be incorrectly denied, which is inconvenient if it concerns something like a food ration or some license required to perform a job. A false non-match in a blacklist system can result in a terrorist entering a country undetected, or somebody being allocated the same resource twice (food rations, licenses).
In a whitelist scenario, a false match could give a corporate spy access to a research department, or allow an illegal immigrant to enter the country. A false non-match on a whitelist will result in disgruntled employees or unnecessary delays a border crossing.
Whitelist errors
For a whitelist, the consequence of a false reject will usually annoy a normal user of the system. We can therefore think of the false non-match rate (FNMR) axis of an ROC curve as the annoyance axis. The other axis with the false match rate (FMR) is the security axis.
Blacklist errors
With blacklists, the annoyance and security axis are switched. The false match rate axis is now the annoyance axis, and the false non-match rate axis is the security axis.
Numbers
It is impossible to give exact numbers for these general categories, but I can give a few guidelines on how to determine the FMR and FNMR settings for a system.
Below, you will find a few sample database sizes associated with ‘tiny’, ‘medium’ and ‘large’.
- Tiny: 1
- Medium: 500
- Large: 106
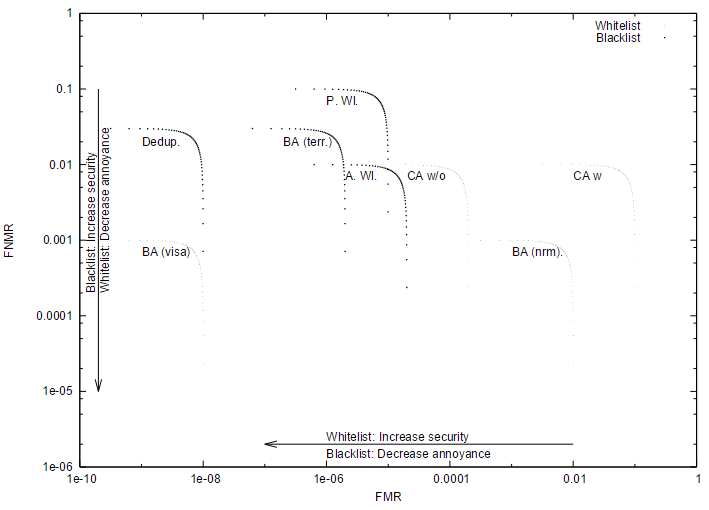
Now depending on the actual implementation, the tradeoff between the annoyance and security factors will be different. As an example I have listed some sample implementations here.
| Scenario | White/blacklist | Database size | Max annoyance | Max security fail | FMR | FNMR |
| Company acces with credentials | White | Tiny | 1% | 10% | 2*10-4 | 1*10-2 |
| Company access without credentials | White | Medium | 1% | 10% | 1*10-1 | 1*10-2 |
| Deduplication | Black | Large | 1% | 3% | 1*10-8 | 3*10-2 |
| Passive watchlist | Black | Medium | 0.50% | 10% | 1*10-5 | 1*10-1 |
| Active watchlist | Black | Medium | 1% | 1% | 2*10-5 | 1*10-2 |
| Regular border access | White | Tiny | 0.10% | 1% | 1*10-2 | 1*10-3 |
| Visa border access | White | Large | 0.10% | 1% | 1*10-8 | 1*10-3 |
| Terrorist check at border | Black | Medium | 0.10% | 3% | 2*10-6 | 3*10-2 |
In the case of border access with a visa, we asusme that this is done through an identification process. This will be the case when a visa is unreadable, lost, or when forgery is suspected.
Using this sample set of values we can construct a figure with aread indicating the maximum allowed values for the algorithm FMR and FNMR. Please note that there is subtlety involved when calculating the algorithm FMR. Given the algorithm FMR&alg and the database size N, the observed system FMRsys is given by FMRsys~=FMRalg*N. The reported values in the tables and figures are all the algorithm FMRalg, which is also reported as the FAR (false accept rate).