A colleague of mine had an interesting problem. He was trying to calculate fill rates for tables in a database, but the only way to access the records was one-by-one. Given that it was a pretty large database, getting the fill rates was quite slow. Because the fill-rates are only displayed with three digit precision in his application (e.g. 94.3%) he was looking for a way to get to an early out when it wasn’t very likely anymore that a specific value was going to change anymore.
This rang a bell because it was pretty similar to a problem I solved some years ago, given the average of some binary variable and the amount of samples, what is the confidence interval. As usually, those types of problems have been solved and beaten to death, the actually problem is usually just finding the relevant solution. For this problem a good solution is the Wilson score interval. It gives you a relation between the average of some binomial variable, the amount of samples and a required confidence for the confidence interval. The results are the upper and lower boundary.
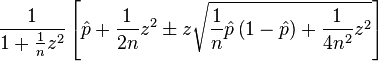
While a bit intimidating, the above is easily expressed in a few lines of code
public static double Lower(double value, double sigma, int sampleCount)
{
double n = (double)sampleCount;
double z = sigma;
double phat = value;
return (phat + z * z / (2 * n) - z * Math.Sqrt((phat * (1 - phat) + z * z / (4 * n)) / n)) / (1 + z * z / n);
}
public static double Upper(double value, double sigma, int sampleCount)
{
double n = (double)sampleCount;
double z = sigma;
double phat = value;
return (phat + z * z / (2 * n) + z * Math.Sqrt((phat * (1 - phat) + z * z / (4 * n)) / n)) / (1 + z * z / n);
}
Note that sigma is the width of a Gaussian, a sane choice is 1.96 which corresponds to a 95% confidence interval.
Using that, we can iteratively search for the lowest value of sampleCount where the minimum of Upper and Lower is smaller than 0.0005 (remember we didn’t want to change the 3-digit representation).
Interestingly enough, the results are highly dependent on the sample count. If the average is around 99.9% (or 0.1%) you only need ~7680 samples. At the center, so close to 50.0% you need at least 4.2 million samples to get the same error boundaries. So unfortunately you can only do early outs for tables that are very sparsely or very densely populated. Anything ‘moderately’ filled will still require many, many samples to get reasonably accurate statistics.